
文章作者:程序员班吉
从这篇文章开始,正式进入到I/O复用模型。而提到I/O复用模型就绕不开select。所以,这篇文章就让我们一起来搞定select的使用。
这篇文章共分为三个部分,第一部分我们先简单介绍一下各个I/O模型以及它们之间的优缺点。第二部分我们使用select实际写代码,最后一部分我们尝试分析一下select的实现原理。
常用I/O模型
在前两篇文章中,我们讨论了阻塞I/O和非阻塞I/O。事实上大部分现代操作系统都不止这两种I/O模型。下面我们就来分析一下常见的几种I/O模型。为了方便大家理解,我重新画了《UNIX网络编程:卷1》中几种常用I/O模型的图例。
阻塞I/O
这也是我们一开始就用到的I/O模型,如下图:
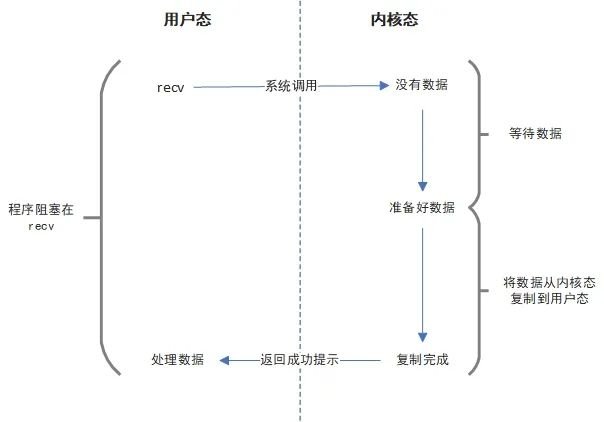
阻塞I/O模型中,我们调用recv、read这类方法的时候,程序会切换到内核态。如果I/O中(网络编程就对应网络套接字)没有数据可读,就会阻塞,直到有可读的数据,内核程序会将数据复制到用户态,复制完成之后返回,recv、read函数返回,这个过程我们已经很熟悉了。
非阻塞I/O
下图中描述了非阻塞I/O的处理流程。
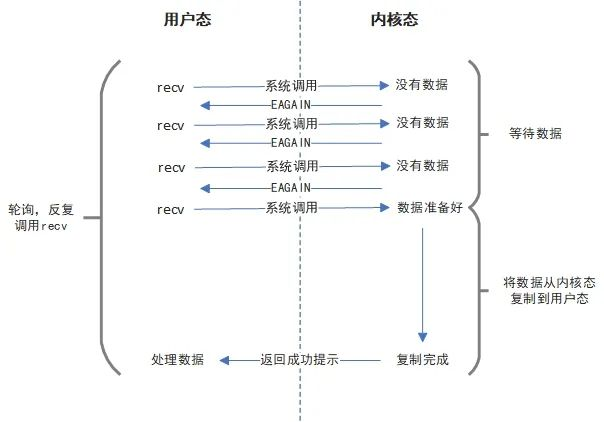
非阻塞I/O虽然不会导致程序的阻塞,但它有一个问题就是我们不确定什么时候有数据可以读。所以,最容易想到的就是将recv放在一个循环中去轮询,如果没有数据,函数返回-1同时errno==EAGAIN。直到有一次调用recv的时候发现有数据可读,这时候内核程序会将数据复制到用户态,复制完成recv函数返回,返回值便是实际读取到的字节长度。
前面在讲非阻塞I/O的时候有提到过,recv调用涉及到内核态和用户态的切换,循环会导致CPU空转,这种方式效率是非常低的。当时我们并没有比较好的解决办法。但是,我们今天要讲的select就能完美的解决这个问题。
基于select的I/O复用模型
在非阻塞I/O那篇文章,我们举了一个例子,假如你是一个很勤奋的程序员,你不停的去催产品经理要需求文档。
这个例子,最好的策略应该是在你上班的时候告诉产品经理,今天需要把文档给到你。然后你就去做你自己的事情了。产品经理文档写好之后发消息通知一下你,这个时候你再去取文档就一定能拿到文档了。
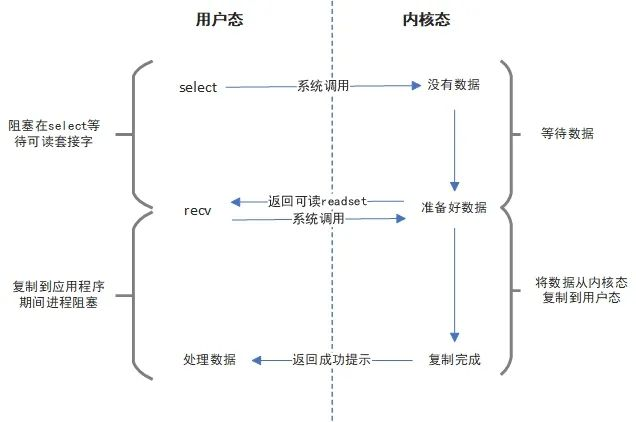
上面这个过程便是select的核心思想。首先,select方法告诉内核程序自己关心哪些I/O描述符,当内核程序发现其中有I/O准备好了(可写/可读/异常)就从select返回,告诉你到底是哪些I/O准备好了,然后你拿着这些准备好的IO再调用recv就一定能拿到数据了,剩下的过程和上面流程是一样的,内核程序会将数据复制到用户态并返回。
你可能会说,不对啊,select不是也会导致阻塞吗?额…你说的没错,这个我们在介绍select实现原理的部分再展开。
可以看到,有了select之后非阻塞I/O和阻塞I/O存在的问题全都解决了,这就是select厉害的地方。
信号驱动I/O模型
要解决轮询的问题,最容易想到的就是发信号,我们通过触发信号来通知应用程序,数据准备好了你可以来读了,如下图:
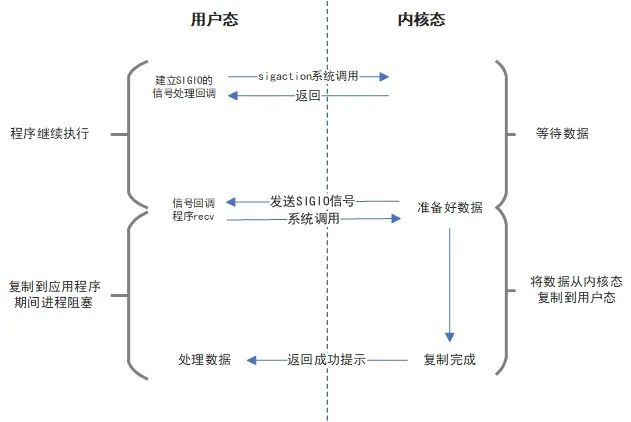
基于信号驱动的I/O模型的流程是,首先我们创建一个处理SIGIO信号的回调函数,当数据准备好了(注意,这里是准备好),内核程序会发送SIGIO信号。此时,我们事先注册的回调函数得以执行。接着也是调用recv函数去读数据,进入内核态,内核程序将数据复制到用户态最后返回。
可以看到,基于信号的I/O也解决了非阻塞IO的轮询问题。但是,基于信号的I/O也有它自己的问题。比如,这种实现首先代码就不是很好写,复杂度提升了,再比如可移植性,不同的操作系统对信号的处理方式可能不一样,兼容性并不好处理。
所以,这种方案虽然可行,但相比I/O复用模型没有什么优势,一般不怎么使用,知道有这种I/O模型就行了。
异步I/O
异步I/O可能是完美主义者最好的选择了,如下:
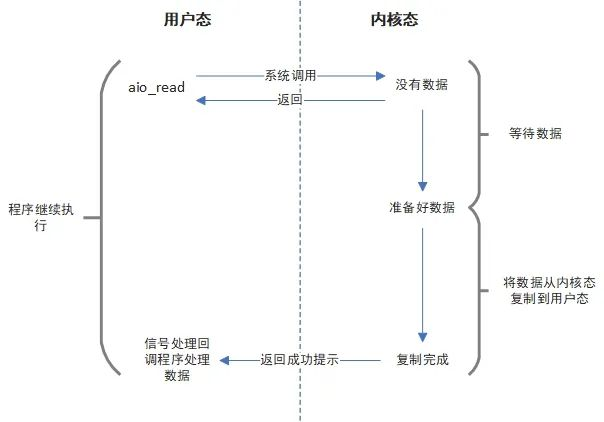
异步I/O先通过aio_read方法调用,如果有数据可读内核程序复制数据到用户态,然后返回。如果没有数据就立即返回。当数据准备好并且成功复制到用户态的时候发送一个信号,信号回调函数处理数据。
这里和基于信号驱动最大的不同是,异步I/O是将数据成功复制到用户态之后才会发送信号。
异步I/O的问题是目前各个操作系统对它的支持都不是很好,不管是可移植性还是可用性都有待完善。
通过对几种I/O模型的分析,我们可以得到一个结论,那就是I/O复用模型现在仍然是高性能I/O程序的首选。所以接下来,我们先来搞明白作为I/O复用的开山鼻祖select到底该怎么用。
select到底怎么用?
select核心就是一个方法,签名如下:
int select(int maxfdp1,
fd_set *readset,
fd_set *writeset,
fd_set *exceptset,
const struct timeval *timeout);
这个方法看起来有点吓人,这么多参数,又是结构体,又是const,搞不明白呀!
对于一个I/O描述符,通常有读、写、异常三种情况,select函数的readset、writeset、exceptset分别就对应了I/O的读、写和异常。表示,当前程序关心readset里描述符是否可读,writeset里的描述符是否可写,exceptset中的描述符是否出现了异常。
只要readset、writeset、exceptset中有一个满足条件,select函数立即返回,返回值是可处理的I/O数量。
那第一个参数是干嘛的呢?
select的第一个参数表示的是当前待监听的描述符基数。比如,当前监听的最大描述符是3,那么参数maxfdp1就应该是4(这是因为描述符是从0开始的)。
你可以思考一下为什么需要这个参数呢?
在select中,用来保存监听集合的数据结构,是一个长度为32的整型数组,这个数组每个元素也是32位的(这大概是因为当时还没64位机器吧)这个数组大概像下面这样:
int32_t fds[32];
这个数组每个元素占32bit,总共就占32*32bit=1024bit。假设每一位代表一个套接字,这个bit如果是0代表不可用。如果是1代表可用。如下:
| 1023 | 1022 | … | 1 | 0 |
| 0 | 1 | … | 1 | 0 |
发现没有,这个数据结构就是一个位图的经典实现。
上面的例子中,在一轮select的调用中,描述符1023不需要处理,1022需要处理,1需要处理,0不需要处理。
我们再回到maxfdp1参数就比较好理解了,当描述符为1023时,maxfdp1就应该是1024。而我们说,select中使用一个长度为32的32位整型数组保存监听套接字集合。所以,select最大可以处理32*32=1024个描述符。
你可能会问,当前描述符大于1023会发生什么呢?答案是,会报错。甚至可能会出现内存溢出的问题。所以,我们在使用select的时候要注意!
最后我们看timeout参数,这个参数是一个结构体,如下:
struct timeval {
long tv_sec; // 秒
long tv_usec; // 微秒
}
这个参数表示,超过一定时间如果还没有可以处理的描述符,直接从select函数返回,返回值为0。
这个参数可能传值有以下几种情况:
- 传NULL,如果没有I/O可以处理,一直等待
- 设置成对应的秒或者微秒,表示select等待相应的时间之后如果没有I/O可以处理就返回
- 将tv_sec和tv_usec都设置成0,表示不用等待立即返回
最后,select函数如果返回-1表示出错,返回0表示超时,返回大于0表示可操作的I/O数量。
搞明白select函数之后,下面我们使用select来写一段代码,如下:
int main(int argc, char *argv[]) {
struct sockaddr_in client_addr;
int conn_fd, serv_fd, max_fd;
char recv_buf[1024], send_buf[1024];
serv_fd = create_sock();
// 将服务端的套接字设置成非阻塞
make_nonblocking(serv_fd);
fd_set read_mask;
fd_set all_reads;
FD_ZERO(&all_reads);
FD_SET(0, &all_reads);
FD_SET(serv_fd, &all_reads);
memset(&client_addr, 0, sizeof(client_addr));
socklen_t cli_len = sizeof(client_addr);
max_fd = serv_fd;
while(1) {
// 将我们判词的可读描述符集合复制一份出来
read_mask = all_reads;
// 注意:第一个参数是最大描述符+1
int rc = select(max_fd + 1, &read_mask, NULL, NULL, NULL);
if (rc < 0) {
perror("select failed.");
exit(1);
}
// 查询serv_fd是否有套接字可以accept
if (FD_ISSET(serv_fd, &read_mask)) {
memset(&client_addr, 0, sizeof(client_addr));
conn_fd = accept(serv_fd, (struct sockaddr *)&client_addr, &cli_len);
if (conn_fd < 0) {
perror("accept failed.");
continue;
}
// 将连接上来的客户端加到readset中
if (conn_fd > max_fd) {
max_fd = conn_fd;
}
FD_SET(conn_fd, &all_reads);
printf("have a new connection: %d.\n", conn_fd);
}
// 查看标准输入是有数据
if (FD_ISSET(STDIN_FILENO, &read_mask)) {
memset(send_buf, 0, sizeof(send_buf));
if (conn_fd <= 0) {
fgets(send_buf, sizeof(send_buf), stdin);
printf("please wait for a connection.\n");
continue;
}
if (fgets(send_buf, sizeof(send_buf), stdin) != NULL) {
int i = strlen(send_buf);
if (send_buf[i - 1] == '\n') {
send_buf[i - 1] = '\0';
}
printf("now send: %s\n", send_buf);
size_t rt = write(conn_fd, send_buf, strlen(send_buf));
if (rt < 0) {
perror("write failed.");
}
printf("send bytes: %zu\n", rt);
}
}
// 查看连接上来的客户端是否有数据可读
if (FD_ISSET(conn_fd, &read_mask)) {
memset(recv_buf, 0, sizeof(recv_buf));
size_t rt = read(conn_fd, recv_buf, sizeof(recv_buf));
if (rt < 0) {
printf("read failed. conn-fd: %d\n", conn_fd);
continue;
}
if (rt == 0) {
printf("client closed, conn-fd: %d\n", conn_fd);
FD_CLR(conn_fd, &all_reads);
close(conn_fd);
continue;
}
printf("from client msg: %s\n", recv_buf);
send(conn_fd, recv_buf, strlen(recv_buf), 0);
}
}
}
上面的代码中,我们通过select管理了三路I/O,第一路是当前服务的socket,第二路是标准输入IO,STDIN_FILENO,第三路是连接上来的客户端socket套接字描述符。首先,我们创建一个服务端的套接字,并设置成非阻塞模式:
serv_fd = create_sock();
// 将服务端的套接字设置成非阻塞
make_nonblocking(serv_fd);
接着,声明两个fd_set,如下:
fd_set read_mask;
fd_set all_reads;
FD_ZERO(&all_reads);
FD_SET(0, &all_reads);
FD_SET(serv_fd, &all_reads);
其中,read_mask用来在一轮select中从all_reads中复制一份出来传给select函数用于检查,all_reads是我们在当前程序中实际维护的一个fd_set集合,这个后面还要详细讲。
这里我们用到了select的2个宏,FD_ZERO、FD_SET,它们的作用如下:FD_ZERO:用于清空描述符集合fd_set
FD_SET:用于将对应的描述符添加到fd_set集合中
除了这两个之外,select还有一个FD_CLR和FD_ISSET宏,分别用于将对应的描述符从fd_set中摘掉和检查当前描述是否可用。
上面代码中,我们先将all_reads集合清空,然后将标准输出(描述符等于0)和serv_fd描述符添加到了all_reads描述符集合中。这样,我们调用select函数的时候内核就会帮我监听这两个描述符是否可读。
接着,我们在一个循环中,调用select函数,如下:
while(1) {
// 将我们判词的可读描述符集合复制一份出来
read_mask = all_reads;
// 注意:第一个参数是最大描述符+1
int rc = select(max_fd + 1, &read_mask, NULL, NULL, NULL);
if (rc < 0) {
perror("select failed.");
exit(1);
}
...
}
我们一上来就将all_reads复制了一份,这是因为传入select的描述符集合会被select修改,如果不复制一份出来可能出现意想不到的结果,这个一定要注意。然后,select的第一个参数我们传入了max_fd+1,到这里为止,当前最大的描述符应该是serv_fd,这个max_fd在上面的代码中已经被赋值了,其值就是serv_fd,如下:
max_fd = serv_fd;
剩下的writeset、exceptset和超时时间都传了NULL。表示我们不关心描述符的可写和异常事件,并且如果拿不到可读的描述符集合一直等待下去。
此时,如果没有可读的描述符,程序会阻塞在select函数,当select函数返回之后,我们就可以检查我们关心的描述符了,首先我们检查的是serv_fd,查看是否有客户端连接上来,如下:
// 查询serv_fd是否有套接字可以accept
if (FD_ISSET(serv_fd, &read_mask)) {
memset(&client_addr, 0, sizeof(client_addr));
conn_fd = accept(serv_fd, (struct sockaddr *)&client_addr, &cli_len);
if (conn_fd < 0) {
perror("accept failed.");
continue;
}
// 将连接上来的客户端加到readset中
if (conn_fd > max_fd) {
max_fd = conn_fd;
}
FD_SET(conn_fd, &all_reads);
printf("have a new connection: %d.\n", conn_fd);
}
我们使用FD_ISSET宏检查serv_fd是否可用,在当前场景下,如果serv_fd可用就表示有客户端连接上来,我们就调用accept拿到客户端的描述符。如果出错,就continue让select继续检查。
接着我们判断如果连上的套接字描述符大于当前最大描述符,就将当前最大描述符置为当前客户端描述符。
紧接着调用FD_SET将连接上来的描述符放到可读描述符集合中。当然,如果没有客户端连接上来的时候,这里的FD_ISSET条件不成立,程序就会继续往下面走了。
// 查看标准输入是有数据
if (FD_ISSET(STDIN_FILENO, &read_mask)) {
memset(send_buf, 0, sizeof(send_buf));
if (conn_fd <= 0) {
fgets(send_buf, sizeof(send_buf), stdin);
printf("please wait for a connection.\n");
continue;
}
if (fgets(send_buf, sizeof(send_buf), stdin) != NULL) {
int i = strlen(send_buf);
if (send_buf[i - 1] == '\n') {
send_buf[i - 1] = '\0';
}
printf("now send: %s\n", send_buf);
size_t rt = write(conn_fd, send_buf, strlen(send_buf));
if (rt < 0) {
perror("write failed.");
}
printf("send bytes: %zu\n", rt);
}
}
上面的代码,判断标准输入是否可读,然后我们还要判断当前是否有客户端连接上来了,如果没有就continue,一直等待。这里一定要注意的是我们要把数据读出来,否则下次循环select会一直认为标准输入可读,就不会阻塞了。有兴趣的话你可以把fgets那一行注释掉试一下。如果有连接上来的客户端,就从标准输入读入内容,然后将读到的数据发送给客户端。最后,我们检查的是客户端描述符,如下:
// 查看连接上来的客户端是否有数据可读
if (FD_ISSET(conn_fd, &read_mask)) {
memset(recv_buf, 0, sizeof(recv_buf));
size_t rt = read(conn_fd, recv_buf, sizeof(recv_buf));
if (rt < 0) {
printf("read failed. conn-fd: %d\n", conn_fd);
continue;
}
if (rt == 0) {
printf("client closed, conn-fd: %d\n", conn_fd);
FD_CLR(conn_fd, &all_reads);
close(conn_fd);
continue;
}
printf("from client msg: %s\n", recv_buf);
send(conn_fd, recv_buf, strlen(recv_buf), 0);
}
当客户端有数据可读我们就读出来,然后又重新发送给客户端。
可以看到,使用select我们可以同时监听多个描述符,在描述符不可用的时候也不会占用CPU资源。
你可以试着不用select实现一下上面的代码,你会发现,不管你怎么写,代码始终会阻塞在其中一个描述符,其它两个在那里干着急。这就是select的强大之处。
当然,上面的代码还有一个缺陷,如果有多个客户端连上来,最新的描述符源源不断的添加到all_reads里,但我们检查的永远是当前的描述符(conn_fd每次都会被赋值为最新的描述符),之前描述符就没机会运行了。你可以想想看并试着解决一下这个问题。
这个问题,我们留到下一篇文章讲poll的时候再来解决。
另外还有一个可以优化的地方,如果标准输入和客户端套接字同时可读,上面的代码我们处理完一个又要回到select调用,而select是系统调用会进行内核态和用户态的切换,你可以思考一下代码应该怎么优化。
如果你只是想了解select怎么使用的,看到这里就可以了,但如果你还想了解select是如何做到的,你可以继续往下看。
select的实现原理
当我们的程序编写好之后,会通过编译器将程序翻译成一条条的机器指令,这些指令通常会保存在一个文件当中。当我们将程序运行起来之后,这个程序文件中的指令会被加载到内存当中,通过控制总线和数据总线发送到CPU去执行。下面我们就来简单回顾一下CPU运行的原理。
CPU通过时钟信号来同步其内部的操作,每个时钟周期都会执行相应的机器指令。我们可以将CPU的时钟信号想象成钟摆,钟摆滴答一次就可以认为是一个时钟周期。
当我们将程序在操作系统中运行起来之后,操作系统会为这个程序分配对应的进程ID,内存空间等信息。然后将进程信息放到一个运行中的队列。操作系统内核的调度程序会不断的从这个队列取出对应程序的机器指令放到CPU去执行。
当然,我们平时在使用计算机的时候,经常同时打开多个应用。看起来它们像是同时在运行。实际上不是的,这只是操作系统的障眼法,内核任务调度器会尽量公平的将CPU的时间分摊到各个应用程序,执行完一定的时钟周期就停下来让其它的程序执行一会儿,就这样一直交替运行,由于CPU执行的很快,我们人类察觉不出来,所以看起来就像是在同时运行。
一颗主频2GHz的CPU,一个时钟周期是0.5纳秒,这是什么概念呢?相当于1秒钟内可以摆动20亿次,假如最理想情况1个时间周期执行1条指令,那么1秒钟可以执行20亿次指令。
下面这张图是多个进程运行的示例
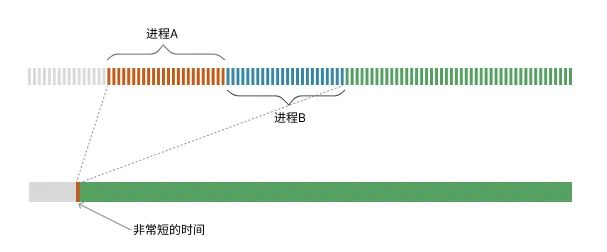
图中,上面部分是整个CPU执行时间线中的一个小片段被放大的样子,时间被切成了非常多的小片段,每一个小片就是一个时钟周期,进程A和进程B在内核调度程序的控制下,分配了时间片,进程A执行一会儿然后进程B再执行一会儿。而在现实中这个时间是非常短的,短到人类察觉不到。
好了,我们上面花了些时间来介绍了CPU执行程序的大致原理。我们思考一个问题,上面我们说基于select的I/O复用模型在调用select的时候会阻塞在select函数上。我们很自然的会想到,这里的阻塞会不会占用CPU呢?
答案是不会的,我们前面讲程序在运行起来之后,首先会将程序的进程信息放到运行队列待内核调度。
select的实现逻辑是,如果当前没有准备好的可操作描述符,会将当前调用select的进程从运行队列中摘掉,然后放到一个等待运行的队列中。此时,调用select的进程就没有运行的机会了,看起来的效果就是被阻塞在了select函数调用上。其流程大致如下:
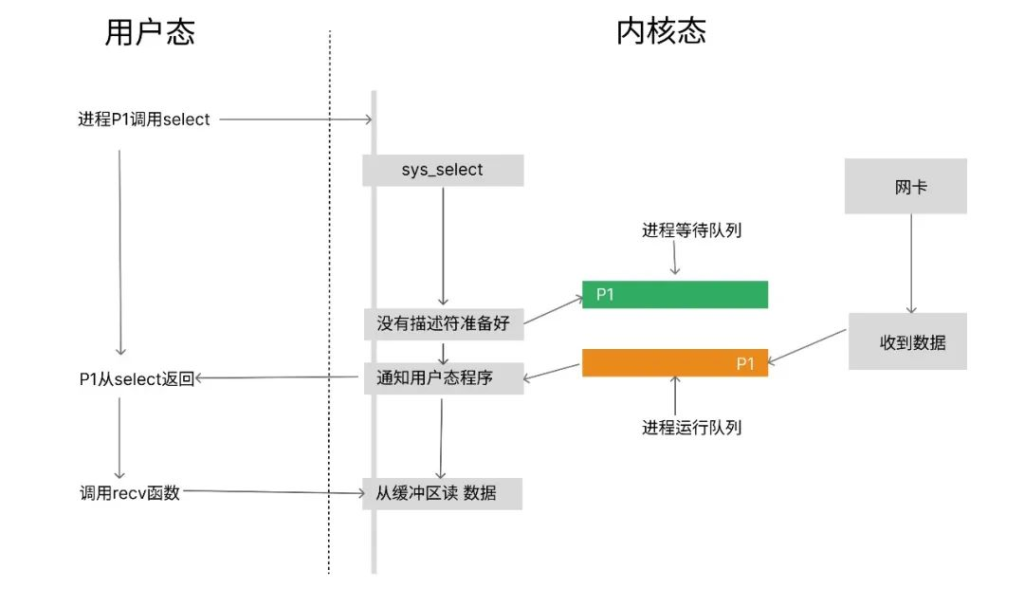
首先,进程P1调用select函数,这个select函数最终会调用操作系统内核的sys_select函数。发现没有准备好的描述符。就将进程P1放到等待运行队列里了。此时,进程P1的现象就像是被挂起了。
接着,过了一会儿网卡收到数据,发现进程P1正在监听当前套接字,内核程序就把进程P1从等待队列里移动到运行队列,让P1有运行的机会。此时,select函数的返回值以及readset都已经被赋值过了,进程P1继续运行,从select函数返回,并且能拿到select返回的数据了。
最后,进程P1再调用recv函数从读缓冲区读取数据。
你可能会有疑问,网卡收到数据之后,怎么知道是select在等待的描述符是哪个呢?这是由于select针对每个描述符都注册了回调函数,当网卡收到数据的时候,首先通过对应的描述符找到回调函数,这个回调函数执行之后,select的返回值和readset的值就被设置好了。
下面,我们通过select的源码来分析一下这个过程,我这里使用的是linux2.6版本的内核代码。
select相关的代码在fs/select.c下面,我们调用select函数最终实际调用的是一个叫sys_select的函数,如下:
asmlinkage long
sys_select(int n, fd_set __user *inp, fd_set __user *outp, fd_set __user *exp, struct timeval __user *tvp)
{
...
// 超时时间默认是一个很在的值,可以认为永远等下去
// 对应的就是参数NULL
timeout = MAX_SCHEDULE_TIMEOUT;
// 如果设置了超时时间,会设置对应的超时
if (tvp) {
...
}
...
// 调用do_select函数查找可用描述符
ret = do_select(n, &fds, &timeout);
...
// 如果结果小于0,跳转到out
if (ret < 0)
goto out;
// 如果结果为0,等待信号
// 其中current是当前进程,也就是我们
// 调用select的那个进程的指针
if (!ret) {
ret = -ERESTARTNOHAND;
if (signal_pending(current))
goto out;
ret = 0;
}
// 这里重写了in/out/ex描述符集合
// 所以为什么我们在检查之后要重置
set_fd_set(n, inp, fds.res_in);
set_fd_set(n, outp, fds.res_out);
set_fd_set(n, exp, fds.res_ex);
out:
select_bits_free(bits, size);
out_nofds:
return ret;
}
然后我们接着看最核心的do_select函数,如下:
int do_select(int n, fd_set_bits *fds, long *timeout)
{
struct poll_wqueues table;
poll_table *wait;
int retval, i;
long __timeout = *timeout;
spin_lock(¤t->files->file_lock);
retval = max_select_fd(n, fds);
spin_unlock(¤t->files->file_lock);
if (retval < 0)
return retval;
n = retval; // 这里的n就是前面我们说的最大描述符+1
poll_initwait(&table);
wait = &table.pt;
if (!__timeout)
wait = NULL;
retval = 0;
for (;;) {
unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp;
set_current_state(TASK_INTERRUPTIBLE);
inp = fds->in; outp = fds->out; exp = fds->ex;
rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex;
// 可以看到,这里是i < n,所以为什么maxfdp1
// 必需是最大描述符+1
for (i = 0; i < n; ++rinp, ++routp, ++rexp) {
// 这个循环里其实就是从in/out/ex中寻找
// 当前数组下标是否有=1的
// 找到之后分别放在res_in、res_out、res_ex中
...
if (res_in)
*rinp = res_in;
if (res_out)
*routp = res_out;
if (res_ex)
*rexp = res_ex;
}
wait = NULL;
if (retval || !__timeout || signal_pending(current))
break;
if(table.error) {
retval = table.error;
break;
}
// 这里很重要,当一轮找下来没找到可用的描述符
// 当前进程就会进入睡眠状态
// 直到有可用的描述符,或者超时
__timeout = schedule_timeout(__timeout);
}
// 返回用户态
__set_current_state(TASK_RUNNING);
poll_freewait(&table);
/*
* Up-to-date the caller timeout.
*/
*timeout = __timeout;
return retval;
}
我们再梳理一下整个流程
- 我们调用select函数实际是调用的是内核中的sys_select函数
- sys_select函数会调用do_select函数,查找是否有可用的描述符
- 在do_select中,有一个无限循环,每一轮都会从0遍历到maxfdp1+1,查找对应的描述字是否可用。
- 如果在一轮寻找中,没有查找到任何可用的描述符,调用schedule_timeout(__timeout)将当前进程放到待运行队列中。
- 当有可用描述符或者超时,当前进程会从睡眠中醒来,调用__set_current_state(TASK_RUNNING)将当前进程放到运行队列中,这样,select函数就返回了。
通过上面的分析,我们发现,select每一轮查找不管有没有可用描述符都会遍历maxfdp1这么多次,直觉上效率并不是很高,页实际情况也是这样的,这个在后面讲poll、epoll的时候你就能有感觉了。
总结
如果你想了解select更详细的实现细节,可以去读一读select的源码。比如,in、out、ex的数据结构到底是怎么设计的,数据是怎么遍历的,entry的回调函数又是怎么被运行的都可以在源码中找到答案。
这篇文章原本是要将上一篇文章中非阻塞套接字的例子使用select改造一下,但是到这里为止又已经快接近8千字了,所以,决定放到下一篇讲poll的时候去解决。
由于涉及到内核源码的原理部分,本人功力有限,如果出现错误还请大家指正!
